- Observability 360
- Posts
- Delta Force - The Edge Becomes The Centre
Delta Force - The Edge Becomes The Centre
The Evaluation Paradox | GitHub Outages - What Went Wrong?
John Hayes
March 20, 2026
Welcome to Edition #44 of the newsletter!
Total Context
We have probably all assumed that the AI revolution would have a transformative effect on observability. The question was - what form will it take? Maybe, at last week’s SRE Day in London, we started to see the answers to that question.
It seems as though one of the major outcomes will be the advent of systems capable of building total context. This means going beyond the traditional signals of observability - logs, metrics, traces - and correlating signals from a multiplicity of other sources.
This is a theme that was demonstrated to spectacular effect in the RunWhen session featured below but also came through strongly in sessions by vendors such as Phoebe and ilert.
The Edge is the Centre?
As we also report this week, Edge Delta have announced a new product that really turns the tables - reimagining the telemetry pipeline as the nerve centre of observability. Can the centre hold?
Feedback
We love to hear your feedback. Let us know how we are doing at:
NEWS
RunWhen’s SRE Day High Wire Act

One of the standout sessions from last week’s SRE Day event in London was this amazing high-wire act by Kyle Forster of RunWhen.
He invited a team of volunteer SREs, who had never previously met, to use RunWhen's AI to investigate an environment they had never seen before. This was pretty much an open invitation to the demo gods to descend on the venue and do their worst.
The upshot though was that fortune favoured the brave. Within 20 minutes, the intrepid volunteers had onboarded themselves to the system, triaged issues, carried out RCA and assigned a ticket. This was quite a stunning vindication of the vision in the image: enabling any engineer to handle any issue in any stack.
We don’t yet have a link to a recording of the session but this LinkedIn post by Kyle should hopefully give you a flavour of the occasion.
Edge Delta - From Pipeline to Agentic Platform

Edge Delta are well known as one of the leading players in the burgeoning data pipeline space. They have now unveiled ambitious plans to reinvent the pipeline as a hybrid observability platform where the workload is shared between the Edge Delta Cloud and a team of AI agents - branded as AI Teammates - running on the edge.
In an interesting product marketing move, the company reached out for feedback on the new offering in this post on reddit. The post seems to be remarkably candid but could also be a gambit to pre-empt misgivings that users may have about a pipeline vendor pivoting into the observability stack role.
It is certainly a pretty audacious flex. The company argue that the advantage of AI Teammates lies in the fact that the pipeline processes the pure, unfiltered data at source, before it has been transformed or sampled. This means that it is capable of detecting possible correlations that might otherwise be lost. What’s more, it can analyse the data in real time without the latency of the data being passed to a downstream data store.
This really puts the cat amongst the pigeons. Shifting observability’s centre of gravity to the edge is a pretty big deal.
“Observability at a Crossroads” - Grafana’s 4th Annual Report
The daffodils are shooting up, the clocks are going forward, and it is time for that other harbinger of springtime - the Grafana Annual Observability Report. The report surveys over 1,300 practitioners across 76 countries and is one of the most authoritative surveys of the observability landscape.
Naturally, AI is one of the biggest themes. The report finds that practitioners are embracing AI but also demanding rigour and traceability: “AI belongs in the observability workflow… and explainability is the price of admission“.
Despite concerns of an Observability Cost Crisis, the survey finds that companies expect to actually spend more on observability in the next year. This is actually not a result of increasing vendor prices but represents a shift towards viewing observability as an investment rather than a cost centre. In fact, as the survey states, for many engineers, complexity is a larger concern than cost.
This is a wide-reaching survey and it is well worth digging into it to see some of the real concerns of practitioners that sometimes don’t necessarily align with vendor selling points.
Azure Roll Out SRE Agent

Microsoft have finally announced the roll out of their own AI SRE for the Azure cloud. The proposition is pretty much as you would expect - it will detect issues, suggest optimisations and reduce toil.
Being an Azure product, the developers naturally have deep inside knowledge of the platform and its internals. As you would expect, therefore, it ships with intelligent defaults as well as automatic integration with Azure Monitor alerts. On top of this, there are also integrations with GitHub, MCP servers and incident management platforms such as PagerDuty and ServiceNow.
You need to purchase the Agent as a separate SKU in your Azure cloud and, unfortunately, the billing model is based on an abstraction called an Azure Agent Unit - which means that initial budgeting can be a bit of a guessing game.
If you have ever used Copilot for Azure then you will know that it was not a particularly rewarding or joined-up experience - but don’t let that put you off. We spun up an Azure SRE Agent and gave it a few simple tests. This involved tasks such as investigating some failing Kubernetes services that we had deliberately misconfigured. The agent successfully diagnosed and remediated the issues and provided a detailed audit trail of its decisions and actions. We don’t have any benchmarks for comparing against other AI SREs but, for us, it passed muster.
Products
OllyGarden - Getting You Ready For Prime Thyme

OllyGarden are really riding the crest of a wave at the moment. They have quickly established themselves as a driving force for improving telemetry standards, will be leading no less than seven talks at next week’s KubeCon Europe and have also just been included in Notion Capital’s Top 100 Cloud Challengers for 2026.
Amidst all the excitement though, they are still managing to ship software. The latest plant to take root in the garden is Thyme. The purpose of Thyme is to answer one of the most important questions about your OpenTelemetry infrastructure - how much load can it take?
Obviously, if you are operating at scale this is a critical question. Thyme is optimised for pushing loads of up to 100k logs per second so that you can stress test your environment and benchmark how much RAM and CPU your Collectors will need in production.
Are You An AI Coding Agent? Then Read On…

Well, sooner or later it had to happen, and now it has. Say hello to Browser Dev Tools MCP - a debugger built not for humans but for agents. So, if you are Claude or Windsurf or Cursor, you may want to hear more. This a is next-generation toolkit that actually helps coding agents to debug visually. Not long ago this would have been science fiction - now it is becoming the new normal for software development.
The depth and range of functionality is highly impressive - screenshots, Playwright-style expressions, ARIA snapshots, oTel support, Figma tools - the full works. Your agent will have no excuse for complaining about its tooling.
A question we have asked ourselves many times recently is “Is this observability or is this debugging?”. We have probably arrived at a moment where that is a moot point. Observability can no longer be an outer-loop concern. Agents are producing and deploying code at warp speed. Observability needs to be deeply embedded in the whole cycle.
From the Blogosphere
GitHub Outages - What Went Wrong?
In the past month or so the GitHub platform suffered a number of well-documented outages which resulted in loss of service for users. In the spirit of transparency, GitHub CTO Vlad Fedorov published this article on the GitHub blog, explaining the causes of the outages and the lessons learned as well as detailing the remediations that GitHub engineers will be putting in place.
The article really brings home the challenges of orchestrating the components of a global technology infrastructure - as well as the compounding effects of working at very large scale. The investigation revealed a perfect storm of edge cases, hidden tipping points and unforeseen knock-on effects. It’s impossible not to feel for the engineers sweating in the war-rooms as the dramas unfolded - after all, watching your failover fail must be pretty gut-wrenching.
As Lorin Hochstein notes in his commentary on Fedorov’s article, you cannot mitigate for every possible eventuality but – taking a leaf out of the Google SRE book - you can develop processes and patterns that facilitate investigation and remediation. If you are interested in the general lessons to be learnt from the GitHub outages it really is worth checking out both articles.
Edwin - Getting to the Root of the Matter

One of the major hard problems in observability is still root cause analysis. Most systems can tell you there is an outage and what services are impacted. Defining the root cause though, is often a journey through a hall of mirrors - causality can be a very elusive customer.
This article on the LogicMonitor blog provides some really interesting insights into the method employed by Edwin - the system’s AI engine. A recurrent theme in the AI SRE domain is the importance of context. Context though can just mean that you have collected a lot of data from a lot of different sources. The article shows the step-by-step logic employed by Edwin in identifying relevant evidence and forming a hypothesis about cause.
It seems that, like flares, logs are making a bit of a comeback. Maybe this is because logging practices are improving, maybe it is because parsing them and detecting patterns is a no-brainer for AI. Maybe, in the court of RCA, the textual record really is the best source of truth - even if it’s not the whole truth.
OpenTelemetry
Working with the oTel Collector Transform Processor
This is yet another outstanding technical walkthrough from the Dash0 blog. At some point, you will almost certainly need to transform the telemetry that is ingested by your oTel Collectors. To achieve the best results, you will need to have an understanding of some of the underlying mechanics of the Transform Processor - including rules governing the order in which operations are carried out and the scopes within which specific commands can be executed.
The article is a great jumping off point for anybody wanting to get started with the Processor. It is a (relatively) long article - but the Processor is a pretty substantial piece of kit and there is a lot of ground to cover. I found this article really useful on a number of levels - not least because the author provides some really useful coverage of the pitfalls and gotchas you might meet along the way.
AI
LLMs - the Evaluation Paradox
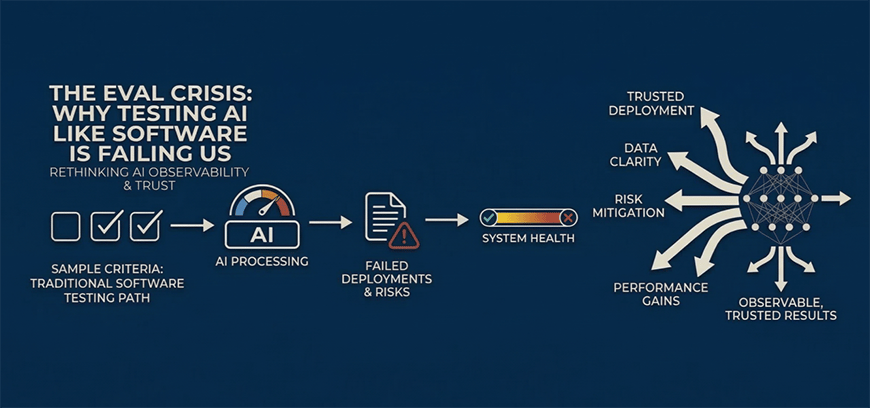
Maths has the Incompleteness Theorems, Quantum Mechanics has the Measurement Problem and now, maybe, AI can proudly boast its own insoluble contradiction - the Evaluation Paradox. We finish up this edition of the newsletter with a really vital and pulsating commentary piece by Yasmeen Ahmad - a Product and GTM Executive at Google. The title (The Eval Crisis: Why Testing AI Like Software is Failing Us) may sound dramatic, but this is not clickbait - it is a fluent and deeply insightful analysis of the fundamental paradoxes at the heart of LLM evaluation.
We all know that LLMs are non-deterministic and are prone to hallucinating. Unfortunately though, human evaluation does not scale. So this leaves us in a doom-loop of LLMs having their homework marked by other LLMs. If your LLM-driven application was an aeroplane, you might not want to fly in it.
This is compounded by the problem that LLMs are exceptionally good at gaming benchmarking suites. In fact, there is even evidence that they alter their behaviours when they know that they are being tested.
That being the case, the talk of a ‘crisis’ is probably well founded. This is an essential read and a great way to tune into a really hot topic in LLM observability.
That’s all for this edition!
If you have friends or colleagues who may be interested in subscribing to the newsletter, then please share this link!
This edition’s quote is from Richard P. Feynman
“The first principle is that you must not fool yourself - and you are the easiest person to fool”.
About Observability 360
Hi! I’m John Hayes. As well as publishing the Observability 360 newsletter, I am also an Observability Advocate at SquaredUp.
The Observability 360 newsletter is entirely independent. All opinions expressed in the newsletter are my own.